Лекция. Архитектура Transformer. Введение, Transformer Encoder

Лекция. Архитектура Transformer. Decoder, QKV AttentionSee more

Transformer models: DecodersSee more

Введение в Vision Transformer. Лекция 11. Глубокое обучениеSee more

Stanford CS25: V1 I Transformers United: DL Models that have revolutionized NLP, CV, RLSee more

Занятие 5. Лекция. Attention, transformers! Переломный момент в истории NLPSee more

The Transformer architectureSee more

Vectors In Transformer Neural NetworksSee more
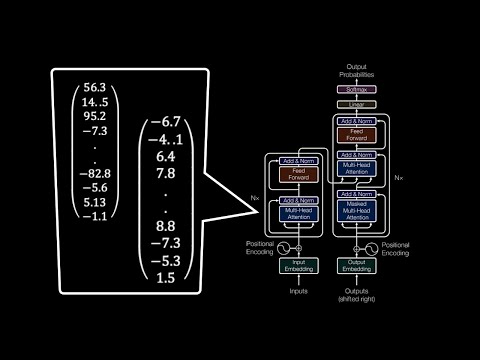
Transformer models: EncodersSee more

Лекция 21. Архитектура "Transformer" для sequence-to-sequenceSee more

L19.5.2.6 BART: Combining Bidirectional and Auto-Regressive TransformersSee more

Attention Is All You Need - Paper ExplainedSee more

NLP Lecture 6(c) - TransformersSee more

Прикладное машинное обучение 4. Self-Attention. Transformer overviewSee more

Transformer models: Encoder-DecodersSee more

Deep Learning: Part5 - Sequence Models (RNN, LSTM, GRU, Transformers)See more

Transformers - Part 1 - Self-attention: an introductionSee more
